
The nthread parameter in XGBoost controls the number of CPU threads used for parallel processing during model training. By leveraging multiple threads, you can significantly reduce the training time, especially when working with large datasets.
This example demonstrates how the nthread parameter affects the model fitting time.
import xgboost as xgb
import numpy as np
from sklearn.datasets import make_classification
import time
import matplotlib.pyplot as plt
# Generate a large synthetic dataset
X, y = make_classification(n_samples=100000, n_classes=2, n_features=20, n_informative=10, random_state=42)
# Define a function to measure model fitting time
def measure_fitting_time(nthread):
start_time = time.perf_counter()
model = xgb.XGBClassifier(n_estimators=100, nthread=nthread)
model.fit(X, y)
end_time = time.perf_counter()
return end_time - start_time
# Test different nthread values
nthread_values = [1, 2, 4, 8, 16]
fitting_times = []
for nthread in nthread_values:
fitting_time = measure_fitting_time(nthread)
fitting_times.append(fitting_time)
print(f"nthread={nthread}, Fitting Time: {fitting_time:.2f} seconds")
# Plot the results
plt.figure(figsize=(8, 6))
plt.plot(nthread_values, fitting_times, marker='o', linestyle='-')
plt.title('nthread vs. Model Fitting Time')
plt.xlabel('nthread')
plt.ylabel('Fitting Time (seconds)')
plt.grid(True)
plt.xticks(nthread_values)
plt.show()
The resulting plot may look as follows:
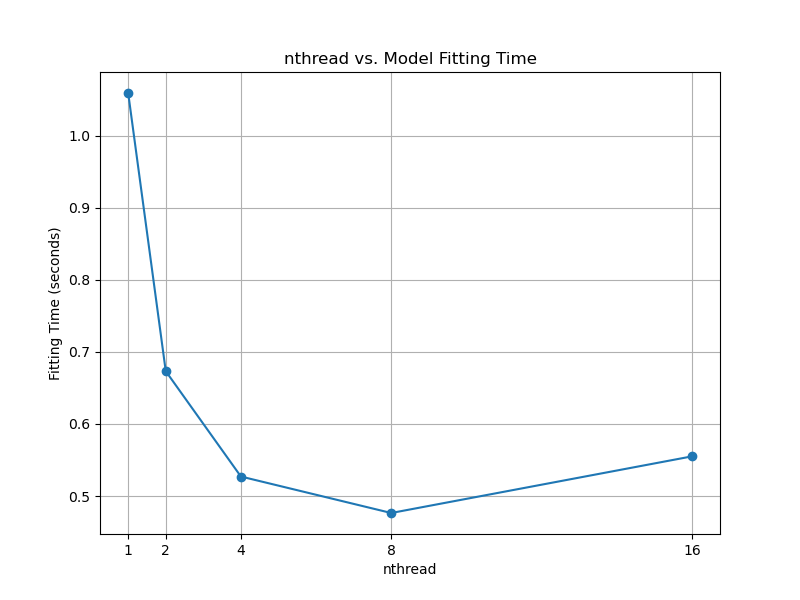
In this example, we generate a large synthetic dataset using scikit-learn’s make_classification function to simulate a realistic scenario where parallel processing can provide significant benefits.
We define a measure_fitting_time function that takes the nthread parameter as input, creates an XGBClassifier with the specified nthread value, fits the model on the dataset, and returns the model fitting time.
We then iterate over different nthread values (1, 2, 4, 8, 16) and measure the model fitting time for each value.
After collecting the fitting times, we plot a graph using matplotlib to visualize the relationship between the nthread values and the corresponding model fitting times.
When you run this code, you will see the fitting times printed for each nthread value, and a graph will be displayed showing the impact of nthread on the model fitting time.
By setting nthread to a higher value, you can potentially reduce the model fitting time significantly, especially when working with large datasets. However, the actual speedup may vary depending on the number of available CPU threads and the specific dataset characteristics.
Note that using a very high nthread value may not always be the optimal choice, as it can lead to high CPU utilization and potentially impact the performance of other processes running on the same machine. It’s recommended to experiment with different nthread values to find the best balance between training speed and resource utilization for your specific use case.