
In this example, we showcase how to use XGBoost as part of a diverse stacking ensemble, which combines the strengths of different models to potentially improve overall performance.
We create a heterogeneous ensemble that includes XGBoost, k-Nearest Neighbor, and Logistic Regression models.
By leveraging the StackingClassifier from scikit-learn, we can easily build a stacking ensemble where XGBoost serves as one of many models, and a meta model learns from the predictions of the base models to make the ultimate prediction.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import StackingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Generate a synthetic multiclass classification dataset
X, y = make_classification(n_samples=1000, n_classes=3, n_features=10, n_informative=6, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define base models
xgb = XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
knn = KNeighborsClassifier(n_neighbors=5)
lr = LogisticRegression()
# Define the stacking ensemble
base_models = [('xgb', xgb), ('knn', knn), ('lr', lr)]
stacking_ensemble = StackingClassifier(estimators=base_models)
# Train and evaluate the stacking ensemble
stacking_ensemble.fit(X_train, y_train)
y_pred_stacking = stacking_ensemble.predict(X_test)
accuracy_stacking = accuracy_score(y_test, y_pred_stacking)
print(f'Stacking Ensemble: {accuracy_stacking}')
# Train and evaluate individual models
xgb.fit(X_train, y_train)
y_pred_xgb = xgb.predict(X_test)
accuracy_xgb = accuracy_score(y_test, y_pred_xgb)
print(f'XGB: {accuracy_xgb}')
knn.fit(X_train, y_train)
y_pred_knn = knn.predict(X_test)
accuracy_knn = accuracy_score(y_test, y_pred_knn)
print(f'KNN: {accuracy_knn}')
lr.fit(X_train, y_train)
y_pred_lr = lr.predict(X_test)
accuracy_lr = accuracy_score(y_test, y_pred_lr)
print(f'LR: {accuracy_lr}')
# Visualize the performance comparison
models = ['XGBoost', 'KNN', 'LR', 'Stacking Ensemble']
accuracies = [accuracy_xgb, accuracy_knn, accuracy_lr, accuracy_stacking]
plt.figure(figsize=(8, 6))
plt.bar(models, accuracies)
plt.title('Model Performance Comparison')
plt.xlabel('Model')
plt.ylabel('Accuracy')
plt.ylim(0.6, 1.0)
plt.show()
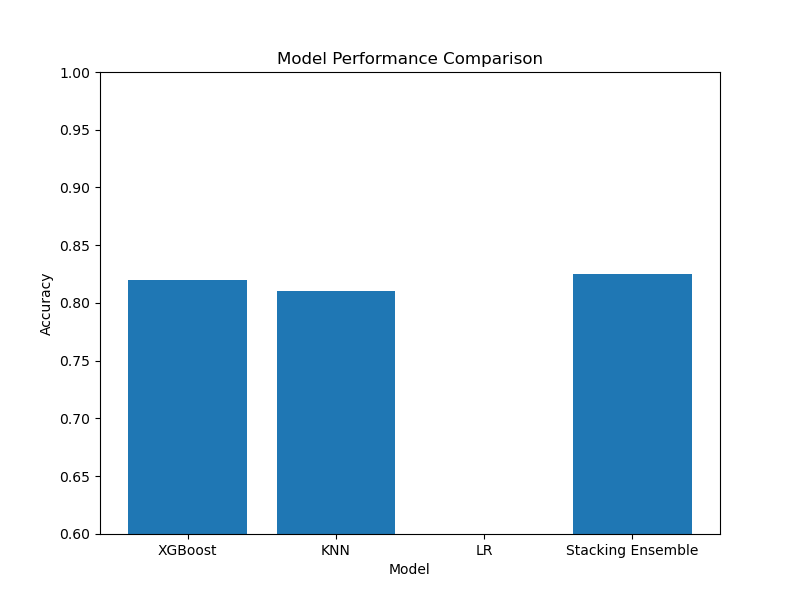
The plot may look like the following:
In this example, we generate a synthetic multiclass classification dataset using scikit-learn’s make_classification function and split it into train and test sets.
We define three base models: XGBoost, KNN, and Logistic Regression. Then, we create a stacking ensemble using the StackingClassifier, specifying the base models and using the default final estimator (Logistic Regression).
We train the stacking ensemble on the training data and evaluate its performance on the test set using accuracy as the metric. We also train and evaluate each individual model for comparison.
Finally, we visualize the performance comparison using a bar plot, which shows the accuracies of the individual models and the stacking ensemble.
By incorporating XGBoost into a diverse stacking ensemble, we can potentially harness the collective power of different algorithms to achieve better performance compared to using XGBoost or any other model alone.