
Stacking ensemble is a powerful technique that combines the predictions of multiple diverse models to make a final prediction.
In this example, we demonstrate how to create a stacking ensemble using multiple XGBoost models with different configurations as base estimators and logistic regression as the final estimator.
By leveraging XGBoost models with diverse hyperparameters, each model can learn different aspects of the data, and the stacking ensemble can combine their predictions to potentially improve overall performance compared to using a single XGBoost model.
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Generate a synthetic multiclass classification dataset
X, y = make_classification(n_samples=1000, n_classes=3, n_features=20, n_informative=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define diverse XGBoost models with different hyperparameters
xgb1 = XGBClassifier(n_estimators=100, max_depth=3, learning_rate=0.1, subsample=0.8, random_state=42)
xgb2 = XGBClassifier(n_estimators=100, max_depth=5, learning_rate=0.05, subsample=0.6, random_state=42)
xgb3 = XGBClassifier(n_estimators=100, max_depth=7, learning_rate=0.01, subsample=1.0, random_state=42)
# Define the stacking ensemble
base_models = [('xgb1', xgb1), ('xgb2', xgb2), ('xgb3', xgb3)]
lr = LogisticRegression()
stacking_ensemble = StackingClassifier(estimators=base_models, final_estimator=lr)
# Train and evaluate the stacking ensemble
stacking_ensemble.fit(X_train, y_train)
y_pred_stacking = stacking_ensemble.predict(X_test)
accuracy_stacking = accuracy_score(y_test, y_pred_stacking)
print(f'Stacking Ensemble: {accuracy_stacking}')
# Train and evaluate individual XGBoost models
xgb1.fit(X_train, y_train)
y_pred_xgb1 = xgb1.predict(X_test)
accuracy_xgb1 = accuracy_score(y_test, y_pred_xgb1)
print(f'XGBoost 1: {accuracy_xgb1}')
xgb2.fit(X_train, y_train)
y_pred_xgb2 = xgb2.predict(X_test)
accuracy_xgb2 = accuracy_score(y_test, y_pred_xgb2)
print(f'XGBoost 2: {accuracy_xgb2}')
xgb3.fit(X_train, y_train)
y_pred_xgb3 = xgb3.predict(X_test)
accuracy_xgb3 = accuracy_score(y_test, y_pred_xgb3)
print(f'XGBoost 3: {accuracy_xgb3}')
# Visualize the performance comparison
models = ['XGBoost 1', 'XGBoost 2', 'XGBoost 3', 'Stacking Ensemble']
accuracies = [accuracy_xgb1, accuracy_xgb2, accuracy_xgb3, accuracy_stacking]
plt.figure(figsize=(8, 6))
plt.bar(models, accuracies)
plt.title('Model Performance Comparison')
plt.xlabel('Model')
plt.ylabel('Accuracy')
plt.ylim(0.8, 1.0)
plt.show()
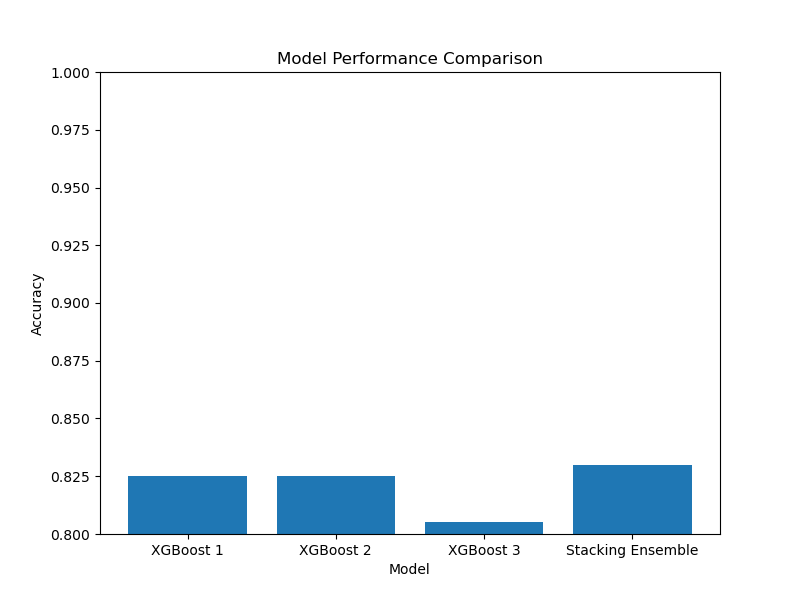
The plot may look like the following:
In this example, we generate a synthetic multiclass classification dataset using scikit-learn’s make_classification function and split it into train and test sets.
We define three diverse XGBoost models with different hyperparameters, such as max_depth, learning_rate, and subsample. These variations allow each model to capture different aspects of the data.
We create a stacking ensemble using the StackingClassifier from the scikit-learn library, specifying the diverse XGBoost models as base estimators (estimators) and logistic regression as the final estimator (final_estimator).
We train the stacking ensemble on the training data and evaluate its performance on the test set using accuracy as the metric. We also train and evaluate each individual XGBoost model for comparison.
Finally, we visualize the performance comparison using a bar plot, which shows the accuracies of the individual XGBoost models and the stacking ensemble.
By using diverse XGBoost models in a stacking ensemble, we can potentially improve the overall performance compared to using a single XGBoost model. The stacking ensemble learns to combine the strengths of the diverse base models, allowing it to make more accurate predictions.