
Bagging, or Bootstrap Aggregating, is an ensemble technique that combines multiple instances of a base model trained on different subsets of the training data.
In this example, we demonstrate how to use XGBoost as the base estimator in a BaggingClassifier for a classification task, showcasing how this ensemble approach can potentially improve performance compared to a single XGBoost model.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, f1_score
import matplotlib.pyplot as plt
# Generate a synthetic classification dataset
X, y = make_classification(n_samples=1000, n_classes=2, n_features=10, n_informative=8, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define the base XGBoost model
xgb = XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
# Create the Bagging ensemble with XGBoost as the base estimator
bagging_xgb = BaggingClassifier(estimator=xgb, n_estimators=10, random_state=42)
# Train and evaluate the single XGBoost model
xgb.fit(X_train, y_train)
y_pred_xgb = xgb.predict(X_test)
accuracy_xgb = accuracy_score(y_test, y_pred_xgb)
f1_xgb = f1_score(y_test, y_pred_xgb)
# Train and evaluate the Bagging ensemble
bagging_xgb.fit(X_train, y_train)
y_pred_bagging = bagging_xgb.predict(X_test)
accuracy_bagging = accuracy_score(y_test, y_pred_bagging)
f1_bagging = f1_score(y_test, y_pred_bagging)
# Print the performance metrics
print(f"Single XGBoost - Accuracy: {accuracy_xgb:.3f}, F1-score: {f1_xgb:.3f}")
print(f"Bagging XGBoost - Accuracy: {accuracy_bagging:.3f}, F1-score: {f1_bagging:.3f}")
# Visualize the performance comparison
models = ['Single XGBoost', 'Bagging XGBoost']
accuracies = [accuracy_xgb, accuracy_bagging]
f1_scores = [f1_xgb, f1_bagging]
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
ax1.bar(models, accuracies)
ax1.set_title('Accuracy Comparison')
ax1.set_ylim(0.8, 1.0)
ax2.bar(models, f1_scores)
ax2.set_title('F1-score Comparison')
ax2.set_ylim(0.8, 1.0)
plt.show()
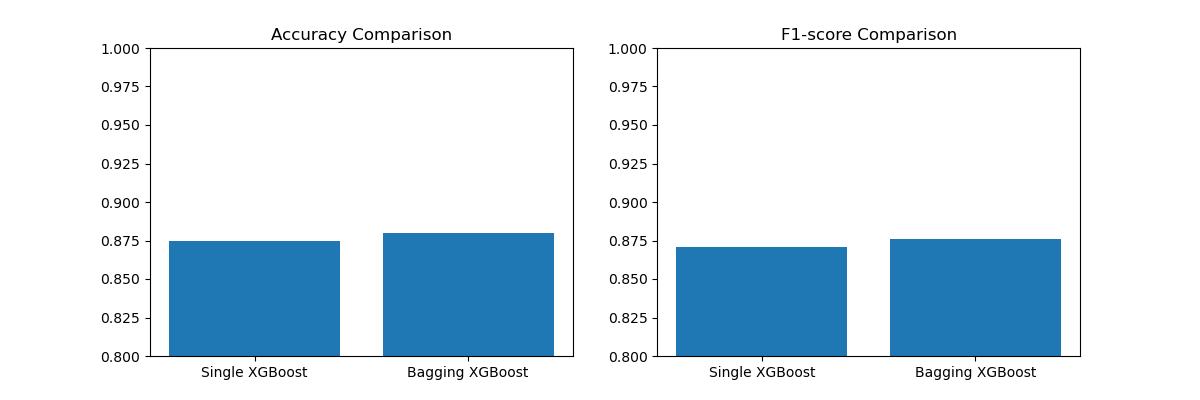
The plot may look like the following:
In this example, we generate a synthetic binary classification dataset using scikit-learn’s make_classification function and split it into train and test sets.
We define a base XGBoost model with specified hyperparameters. Then, we create a BaggingClassifier with this XGBoost model as the base estimator and set the number of bagging iterations.
We train and evaluate the single XGBoost model and the Bagging ensemble on the test set using accuracy and F1-score as the performance metrics.
Finally, we visualize the performance comparison using a side-by-side bar plot, which shows the accuracy and F1-score of the single XGBoost model and the Bagging ensemble.
By using XGBoost as the base estimator in a Bagging ensemble, we can potentially improve the model’s generalization performance and robustness. The Bagging ensemble helps reduce overfitting and variance by training multiple XGBoost models on different bootstrap samples of the training data and combining their predictions.
Note that the performance improvement may vary depending on the dataset and the specific problem at hand. It’s always recommended to evaluate the ensemble approach against the single model to determine if it provides a significant benefit for your particular use case.