
Early stopping is a regularization technique that prevents overfitting by halting the training process when the model’s performance on a validation set stops improving.
In XGBoost, the early_stopping_rounds parameter determines the number of rounds to wait for improvement before stopping training.
We cannot grid search this hyperparameter automatically using the GridSearchCV class because early stopping requires a validation set taken from the train set on each cross validation fold. Using the test set or the validation set for each evaluation would not be valid. Therefore, we must tune the early_stopping_rounds via grid search manually.
This example demonstrates how to tune the early_stopping_rounds parameter using a manual grid search with cross-validation.
import xgboost as xgb
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Create a synthetic dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, random_state=42)
# Configure cross-validation
n_splits = 5
kf = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=42)
# Define hyperparameter grid
early_stopping_rounds = [3, 6, 9, 12, 15,18]
# Perform cross-validation
best_params = None
best_score = 0
best_rounds = None
# Arrays to store scores and best rounds for plotting
scores = []
rounds_list = []
for rounds in early_stopping_rounds:
test_scores = []
for train_index, test_index in kf.split(X, y):
X_train_fold, X_test_fold = X[train_index], X[test_index]
y_train_fold, y_test_fold = y[train_index], y[test_index]
# Split train set into train and validation
X_train_fold, X_val, y_train_fold, y_val = train_test_split(X_train_fold, y_train_fold, test_size=0.2, random_state=42)
# Prepare the model
model = xgb.XGBClassifier(n_estimators=1000,
learning_rate=0.1,
max_depth=2,
early_stopping_rounds=rounds,
objective='binary:logistic',
random_state=42)
# Fit model on train fold and use validation for early stopping
model.fit(X_train_fold, y_train_fold, eval_set=[(X_val, y_val)], verbose=False)
# Predict on test set
y_pred_test = model.predict(X_test_fold)
test_score = accuracy_score(y_test_fold, y_pred_test)
test_scores.append(test_score)
# Compute average score across all folds
average_score = np.mean(test_scores)
if average_score > best_score:
best_score = average_score
best_rounds = rounds
scores.append(average_score)
rounds_list.append(rounds)
print(f"Best early_stopping_rounds: {best_rounds}")
print(f"Best CV Average Accuracy: {best_score}")
# Plotting
plt.figure(figsize=(10, 6))
plt.plot(rounds_list, scores, marker='o', linestyle='-', color='b')
plt.title('Early Stopping Rounds vs Accuracy')
plt.xlabel('Early Stopping Rounds')
plt.ylabel('CV Average Accuracy')
plt.grid(True)
plt.show()
The resulting plot may look as follows:
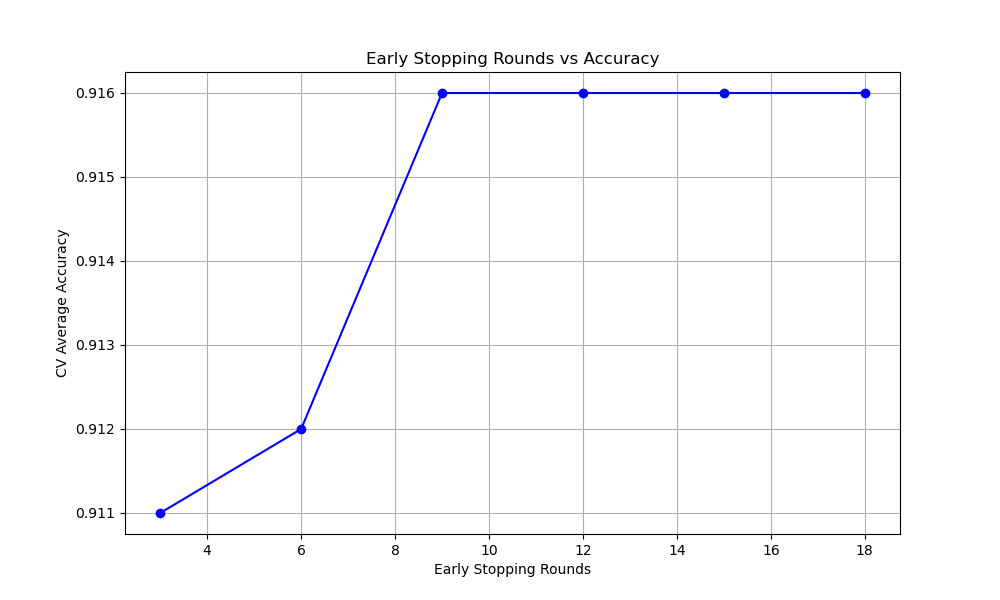
In this example, we demonstrate how to tune the early_stopping_rounds hyperparameter in XGBoost using cross-validation. We create a synthetic binary classification dataset using scikit-learn’s make_classification function.
We configure the cross-validation settings by specifying the number of splits (n_splits) and using StratifiedKFold to ensure that the class distribution is preserved in each fold. We also define a grid of values for early_stopping_rounds that we want to test.
We then perform a grid search over the early_stopping_rounds values using cross-validation. For each value of early_stopping_rounds, we do the following:
- We split the data into train and test folds using
StratifiedKFold. - For each fold:
- We further split the train fold into a training set and a validation set using
train_test_split. - We create an instance of the
XGBClassifierwith the currentearly_stopping_roundsvalue and other specified hyperparameters. - We fit the model on the training fold using
model.fit(), providing the validation set for early stopping via theeval_setparameter. - We predict on the test fold using
model.predict()and calculate the accuracy score. - We append the accuracy score to the
test_scoreslist.
- We further split the train fold into a training set and a validation set using
- We compute the average accuracy score across all folds for the current
early_stopping_roundsvalue. - If the average score is better than the current best score, we update the
best_score,best_rounds, andbest_params. - We append the average score and the corresponding
early_stopping_roundsvalue to thescoresandrounds_listarrays for plotting.
After the grid search, we print the best early_stopping_rounds value and the corresponding best cross-validation average accuracy.
Finally, we plot the relationship between the early_stopping_rounds values and the cross-validation average accuracy scores using matplotlib. This visualization helps us understand how the choice of early_stopping_rounds affects the model’s performance.
By tuning the early_stopping_rounds hyperparameter using cross-validation, we can find the optimal value that balances the model’s performance and training time. This helps prevent overfitting and ensures that the model generalizes well to unseen data. The plot provides insights into the sensitivity of the model’s performance to the early_stopping_rounds value, allowing us to make an informed decision on the best value to use for our specific problem.