
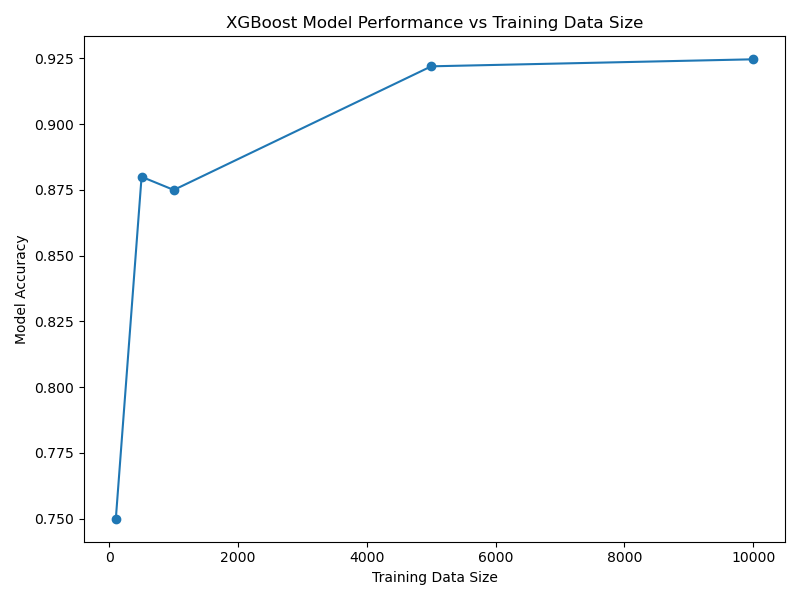
Increasing the size of the training dataset can lead to improved XGBoost model performance.
This example generates a synthetic dataset, trains XGBoost models on different sized subsets of the data, and plots the model performance versus training data size.
The plot illustrates how model skill typically improves as more training examples are provided.
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
import matplotlib.pyplot as plt
# Generate a synthetic classification dataset
X, y = make_classification(n_samples=10000, n_features=20, n_informative=10, n_redundant=5, random_state=42)
# Define a function to train an XGBoost model and return its accuracy
def train_and_evaluate(X_train, y_train, X_test, y_test):
model = XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
return accuracy
# Define an array of training data sizes to test
train_sizes = [100, 500, 1000, 5000, 10000]
# Train models and store accuracies for each training data size
accuracies = []
for size in train_sizes:
if size == X.shape[0]:
X_subset, _, y_subset, _ = train_test_split(X, y, random_state=42, stratify=y)
else:
X_subset, _, y_subset, _ = train_test_split(X, y, train_size=size, random_state=42, stratify=y)
X_train, X_test, y_train, y_test = train_test_split(X_subset, y_subset, test_size=0.2, random_state=42, stratify=y_subset)
accuracy = train_and_evaluate(X_train, y_train, X_test, y_test)
accuracies.append(accuracy)
# Plot the model accuracies versus training data sizes
plt.figure(figsize=(8, 6))
plt.plot(train_sizes, accuracies, marker='o')
plt.xlabel('Training Data Size')
plt.ylabel('Model Accuracy')
plt.title('XGBoost Model Performance vs Training Data Size')
plt.tight_layout()
plt.show()
Running the example, the resulting plot may look as follows:
The code snippet first generates a synthetic classification dataset using scikit-learn’s make_classification function. A train_and_evaluate function is defined to train an XGBoost model on a given training set and return the model’s accuracy on a held-out test set.
An array of different training data sizes is created to test the model’s performance at various data volumes. For each training data size, the code samples the specified number of examples from the full dataset, splits the sampled data into train and test sets, trains an XGBoost model on the train set, and evaluates its accuracy on the test set. The training data sizes and corresponding model accuracies are stored.
Finally, the model accuracies are plotted against the training data sizes using Matplotlib.
The resulting plot shows an increasing trend in model performance as the training data size grows, with diminishing returns at higher data volumes. This example demonstrates the importance of having a sufficient amount of training data to achieve good model performance and highlights the typical relationship between training data size and model skill for XGBoost models.