
XGBoost, a powerful gradient boosting library, provides multiple ways to calculate feature importance scores.
Each score offers a different perspective on the utility of features in the model.
Understanding the differences between these scores is crucial for selecting the most appropriate one for your specific task and interpreting the results effectively.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
from xgboost import plot_importance
import matplotlib.pyplot as plt
# Generate a synthetic dataset
X, y = make_classification(n_samples=1000, n_classes=2, n_features=10,
n_informative=5, n_redundant=2, random_state=42)
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train an XGBoost classifier
model = XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
# Calculate and plot different feature importance scores
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(15, 5))
ax1.set_title('Gain-based Importance')
plot_importance(model, ax=ax1, importance_type='gain')
ax2.set_title('Split-based Importance')
plot_importance(model, ax=ax2, importance_type='weight')
ax3.set_title('Cover Importance')
plot_importance(model, ax=ax3, importance_type='cover')
plt.tight_layout()
plt.show()
The plots may look as follows:
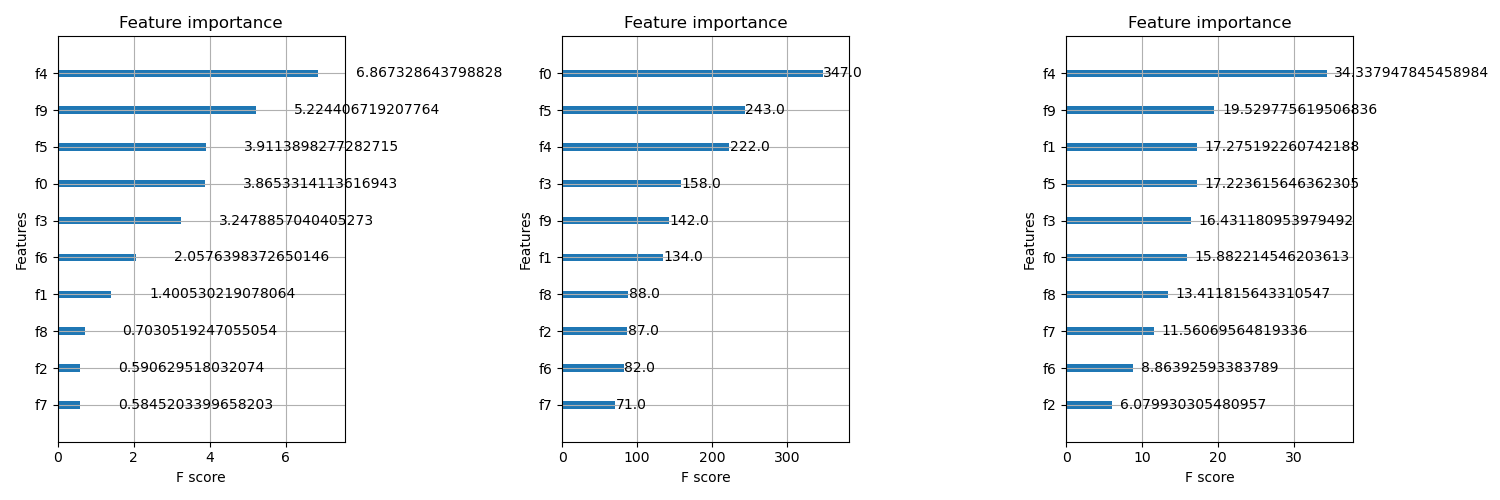
XGBoost offers three main types of feature importance scores:
Gain-based Importance: This score measures the average gain of splits that use a particular feature. The gain represents the improvement in accuracy brought by a feature to the branches it is on. Features with higher gain are considered more important. Gain-based importance is useful for assessing a feature’s general utility, especially in tree-based models. However, it can be biased towards high-cardinality features.
Split-based Importance: Also known as “weight” or “frequency” importance, this score counts the number of times a feature is used to split the data across all trees in the model. Features used more frequently are deemed more important. Split-based importance is simple and intuitive, making it useful for quick, initial feature filtering or when interpretability is crucial. However, it doesn’t account for a feature’s actual impact on predictions.
Cover-based Importance: This score measures the average coverage of splits that use the feature. Coverage represents the number of samples affected by the split.
Other types include total gain and total cover across all trees rather than an average score.
When choosing the appropriate feature importance score, consider the following guidelines:
- Use gain-based and cover-based importance for general feature utility assessment, especially with tree-based models.
- Use split-based importance for quick, initial feature filtering or when interpretability is crucial.
It’s essential to consider multiple scores and domain knowledge when making feature selection decisions. Experimenting with different scores on your specific dataset can provide valuable insights into the relevance and impact of each feature.
There is no best score, only different ways of looking at how the model considered the input features.
XGBoost provides various feature importance scores, each with its strengths and weaknesses. Understanding the differences between these scores is key to selecting the most appropriate one for your task and interpreting the results effectively. By leveraging feature importance scores, you can enhance model interpretability, guide feature selection, and ultimately improve the performance of your XGBoost models.