
Feature importance is a crucial concept in machine learning that helps data scientists and machine learning engineers interpret and understand their models better. XGBoost, being a powerful and widely-used algorithm, provides built-in methods to calculate feature importance scores. By understanding which features contribute the most to the model’s predictions, practitioners can gain valuable insights and make informed decisions in their projects.
What is Feature Importance?
Feature importance refers to the scores assigned to input features based on their contribution to the model’s predictions. In other words, it quantifies how much each feature influences the model’s decision-making process. Features with higher importance scores are considered more influential in determining the output, while features with lower scores have less impact.
Why Measure Feature Importance?
There are several key benefits to measuring feature importance:
Model Interpretability: By understanding which features drive the model’s predictions, data scientists can better interpret the model’s behavior and explain it to stakeholders. This transparency is crucial in many domains, such as healthcare or finance, where decisions must be justified.
Feature Selection: Feature importance scores can guide feature selection by identifying the most relevant variables and discarding irrelevant or noisy ones. This can lead to simpler, more efficient models that are less prone to overfitting.
Insight Generation: Analyzing feature importances can uncover valuable insights and knowledge about the problem domain. By identifying the most influential factors, data scientists can gain a deeper understanding of the underlying processes and make data-driven recommendations.
How XGBoost Calculates Feature Importance
XGBoost provides two main methods for calculating feature importance:
Gain-based Importance: This method measures the average gain of splits that use a particular feature. The gain is the improvement in accuracy brought by a feature to the branches it is on. Features with higher gain are considered more important.
Split-based Importance: Also known as “weight” or “frequency” importance, this method counts the number of times a feature is used to split the data across all trees in the model. Features used more frequently are deemed more important.
Applications of Feature Importance
Understanding feature importance has numerous applications in data science projects:
Model Performance Improvement: By focusing on the most important features and removing irrelevant ones, data scientists can improve model performance and reduce overfitting.
Stakeholder Communication: Feature importance scores provide a clear and interpretable way to communicate the model’s key drivers to non-technical stakeholders, facilitating better decision-making.
Data Collection and Feature Engineering: Knowing which features are most influential can guide data collection efforts and help prioritize feature engineering tasks, ensuring that the most valuable information is captured and processed.
Example: Calculating Feature Importance in XGBoost
Let’s illustrate the concept of feature importance with a simple, synthetic dataset. Suppose we have a dataset of customer churn in a telecommunications company, with features like customer age, monthly charges, contract type, and customer service calls.
import numpy as np
from sklearn.datasets import make_classification
from xgboost import XGBClassifier
from xgboost import plot_importance
import matplotlib.pyplot as plt
# Generate a synthetic dataset
X, y = make_classification(n_samples=1000, n_classes=2, n_features=5,
n_informative=3, n_redundant=1, random_state=42)
# Train an XGBoost classifier
model = XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X, y)
# Plot feature importances
plot_importance(model)
plt.show()
The plot may look as follows:
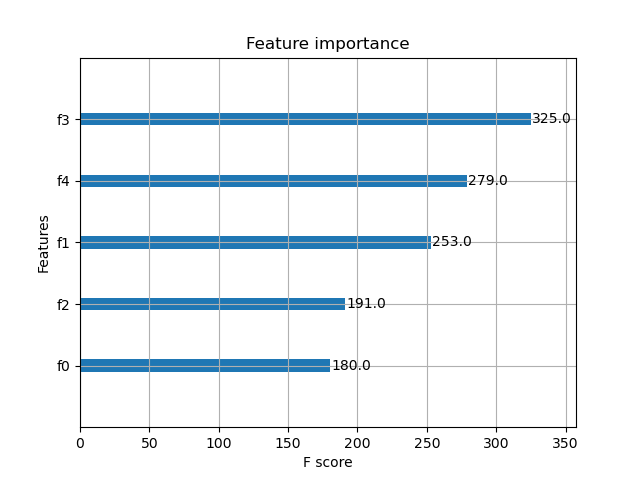
In this example, we generate a synthetic dataset using make_classification from scikit-learn, with 5 features, 3 of which are informative and 1 is redundant. We then train an XGBoost classifier on this data and plot the feature importances using the built-in plot_importance function.
The resulting plot will display the relative importance of each feature, allowing us to identify the most influential variables in the model. By understanding feature importance, data scientists and machine learning engineers can make informed decisions about feature selection, model interpretation, and data collection, ultimately leading to more effective and efficient machine learning solutions.