
Feature selection is an essential step in machine learning to identify the most relevant features, reduce dimensionality, and improve model performance.
XGBoost provides feature importance scores that can be leveraged with scikit-learn’s SelectFromModel for iterative feature selection.
This example demonstrates how to iterate over different importance thresholds, remove features, and evaluate model performance on a test set to find the optimal threshold that maximizes performance while reducing dimensionality.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from xgboost import XGBClassifier
from sklearn.feature_selection import SelectFromModel
import numpy as np
import matplotlib.pyplot as plt
# Generate a synthetic dataset with 100 features (20 informative, 80 redundant)
X, y = make_classification(n_samples=1000, n_features=100, n_informative=20, n_redundant=80, random_state=42)
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train an XGBoost model
model = XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
model.fit(X_train, y_train)
# Get the feature importance scores
importance_scores = model.feature_importances_
# Define a range of threshold values
thresholds = np.sort(model.feature_importances_)
# Initialize lists to store the results
num_features = []
accuracies = []
# Iterate over the threshold values
for threshold in thresholds:
# Select features using the current threshold
selector = SelectFromModel(model, threshold=threshold, prefit=True)
X_train_selected = selector.transform(X_train)
X_test_selected = selector.transform(X_test)
# Train a new XGBoost model with the selected features
selected_model = XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
selected_model.fit(X_train_selected, y_train)
# Evaluate the model on the test set
y_pred = selected_model.predict(X_test_selected)
accuracy = accuracy_score(y_test, y_pred)
# Store the number of selected features and accuracy
num_features.append(X_train_selected.shape[1])
accuracies.append(accuracy)
# Report progress
print(f'> threshold={threshold}, features={X_train_selected.shape[1]}, accuracy={accuracy}')
# Plot the results
plt.figure(figsize=(8, 6))
plt.plot(num_features, accuracies, marker='o')
plt.xlabel('Number of Selected Features')
plt.ylabel('Accuracy')
plt.title('Accuracy vs. Number of Selected Features')
plt.grid(True)
plt.show()
# Find the optimal threshold
optimal_threshold_index = np.argmax(accuracies)
optimal_threshold = thresholds[optimal_threshold_index]
optimal_num_features = num_features[optimal_threshold_index]
print(f"Optimal Threshold: {optimal_threshold:.4f}")
print(f"Number of Selected Features: {optimal_num_features}")
print(f"Accuracy at Optimal Threshold: {accuracies[optimal_threshold_index]:.4f}")
The resulting plot may look as follows:
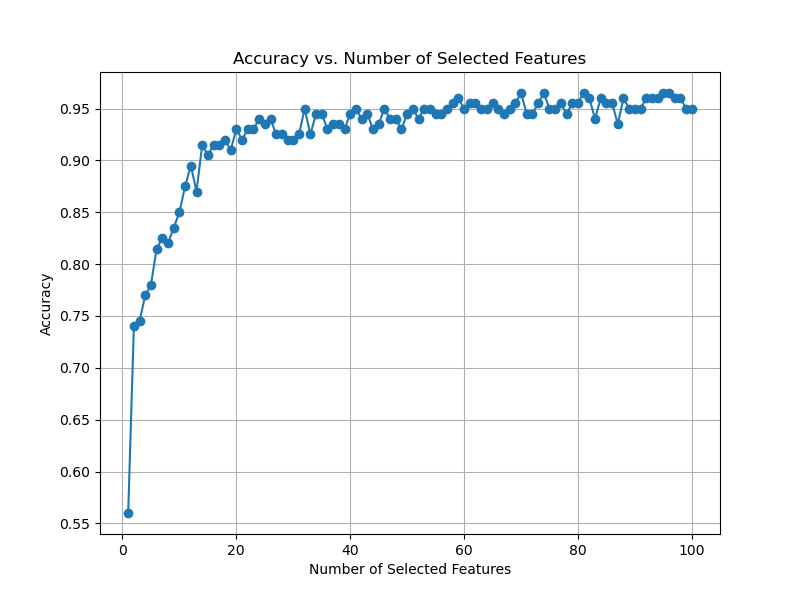
In this example, we generate a synthetic dataset with 100 features, where 20 features are informative, and 80 are redundant. We split the data into train and test sets and train an XGBoost model to obtain feature importance scores.
We then define a range of threshold values and iterate over them using SelectFromModel. For each threshold, we select features, train a new XGBoost model using the selected features, and evaluate its performance on the test set. We store the number of selected features and the corresponding accuracy for each threshold.
After iterating over all thresholds, we plot the accuracy against the number of selected features to visualize the relationship between dimensionality reduction and model performance.
Finally, we find the optimal threshold that maximizes accuracy and print the corresponding number of selected features and the accuracy achieved at that threshold.
This iterative feature selection approach using XGBoost and SelectFromModel allows data scientists and machine learning engineers to identify the most informative features while maintaining or improving model performance. By visualizing the trade-off between the number of features and accuracy, they can make informed decisions about the optimal feature subset for their specific problem.